Геозависимость запроса в Яндексе является одним из важнейших параметров в алгоритме ранжирования. И если вы хотите реально понимать, как ранжируются те или иные запросы, какие запросы будет эффективно комбинировать для одной посадочной страницы, а какие – нет, вам необходимо уметь определять их основные параметры, а не слепо полагаться на результаты работы так называемых «кластеризаторов по топу».
Немногим менее года назад я представил рабочий на тот момент универсальный способ определения геозависимости запроса в Яндексе с использованием только документированных операторов языка запросов. Настоятельно рекомендую внимательно перечесть ту статью, чтобы иметь полное представление о логике данного метода. Вкратце же – этот метод базируется на основополагающем принципе – в выдаче Яндекса для геозависимых запросов в сниппетах наблюдается подстветка топонима, соответствующего региону выдачи, а для геонезависимых – нет. Суть метода заключается в построениие выдачи, в которой для любого проверяемого (исходного) запроса мы сможем гарантировано увидеть на первой странице сниппет, содержащий нужный нам топоним, по наличию подсветки которого мы сможем сделать вывод о геозависимости проверяемого запроса.
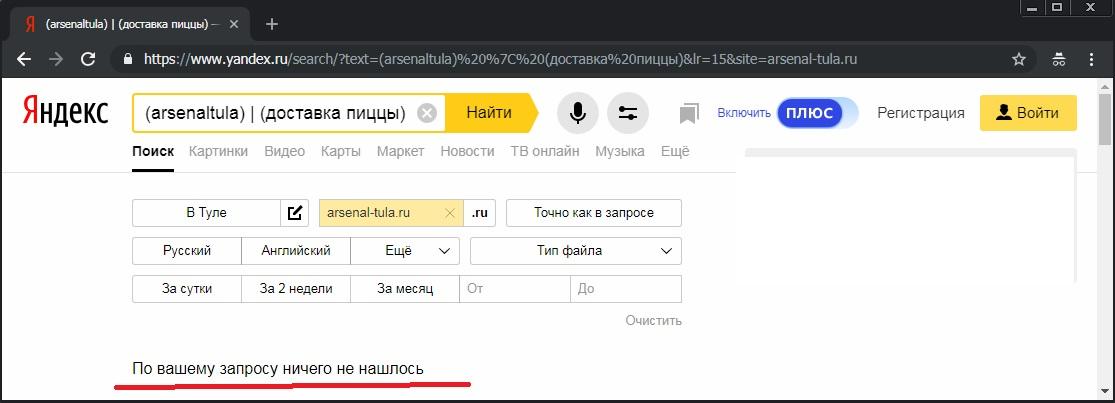
К сожалению, упомянутый метод не так давно потерял свою работоспособность. Судя по всему, неожиданным образом потерялась логика группировки запроса на две независимые части по разные стороны от оператора | («логическое ИЛИ»). То есть по факту Яндекс этот оператор игнорирует, и выдачи как с ним, так и без него идентичны:
Вообще, с логикой работы даже документированных операторов языка запросов в последнее время в Яндексе творятся очень странные вещи. Но как бы то ни было, постараемся понять, чем грозит методу подобная реакция поиска на запрос? А тем, что метод уже не является универсальным, и может не давать результатов для целого класса запросов, содержащих в себе такие ключевые слова, для которых на сайте, выбранном для сужения запроса, не найдется релевантных документов. Например:
То есть нам необходимо вернуть потерянную группировку двух частей запроса. Удивительно, но в этом нам может помочь уже официально списанный Яндексом в утиль оператора группировки () («круглые скобки»). О прекращении поддержки этого оператора наряду с некоторыми другими было объявлено 31 января 2017 года, вскоре он исчез из официальной документации. Но, тем не менее, на текущий момент частично сохранил свою работоспособность.
Для начала хочу внести небольшую, но важную поправку к своей предыдущей статье о методе определения геозависимости. Тогда я писал о том, что «изучая свойства геозависимости запросов, я обратил внимание на тот факт, что добавление к исходному запросу через документированный оператор | (логическое ИЛИ) какого-либо достаточно редкого термина (т.е. имеющего достаточно большое значение IDF – обратной частоты встречаемости в коллекции документов)».
Но, к сожалению, забыл добавить, что для корректной работы метода, этот термин с большим IDF должен быть обязательно геонезависимым. То есть геозависимость запроса, состоящего из двух частей, разделенных оператором | («логическое ИЛИ») есть логическая сумма (дизъюнкция) значений геозависимости этих двух частей, при этом значению 1 («ИСТИНА») соответствуют геозависимые запросы, а значению 0 («ЛОЖЬ») - геонезависимые. И поэтому только в том случае, когда добавочный запрос является геонезависимым, геозависимости исходного запроса и конечного составного запроса совпадают.
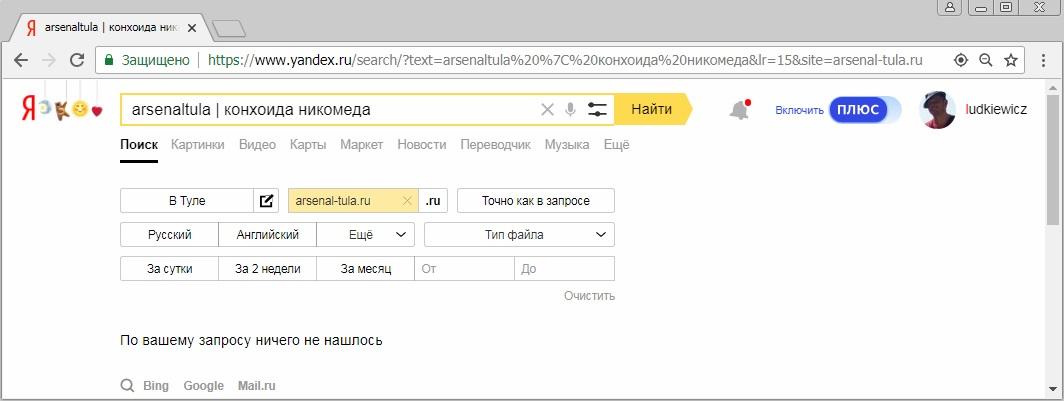
Правда, в оправдание своей забывчивости я могу сказать, что в подавляющем своем большинстве запросы с большим IDF являются геонезависимыми, поэтому вероятность при его случайном выборе ошибки была невелика. Собственно, выбранный мною добавочный запрос, состоящий из термина arsenaltula, как раз и является геонезависимым, в чем мы убедимся несколько позже.
Итак, конструируем новый запрос, который бы сохранил логику работы предыдущего. Для начала нам понадобится выбрать другой тестовый сайт, так как у сайта, использовавшегося в примерах предыдущей статьи из заголовков страниц исчез топоним «Тула». По подсветке которого в сниппетах выдачи для соответствующего региона «Тула» (lr=15) и определяется геозависимость запроса. Я просто заменю официальный сайт тульского футбольного клуба «Арсенал» на сайт его болельщиков, доменное имя которого отличается от предыдущего только наличием дефиса, и страницы которого также релевантны выбранному добавочному запросу. И, что немаловажно, содержат в заголовках нужный топоним, отображаемый в сниппетах. Заодно по отсутствию подсветки топонима в сниппетах убедимся в том, что выбранный добавочный запрос действительно геонезависим:
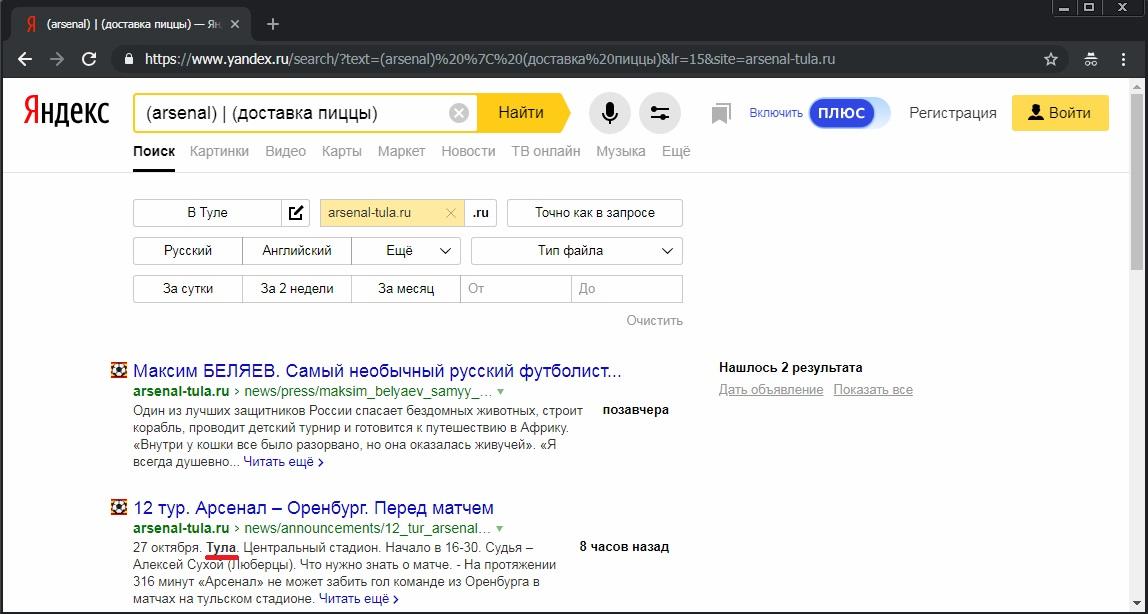
Далее пробуем заключить в скобки обе части запроса из предыдущего метода. И, к моему огромному удивлению, получаем опять пустую выдачу:
Эпик фейл? Недокументированный оператор уже не работает? Но не тут-то было! Получается, что при таком применении – да, действительно не работает. Но неисповедимы пути Яндекса, и стоит нам поменять местами части запроса, как мы чудесным образом получаем нужный нам результат. По отсутствию подсветки в сниппетах говорящий нам, что базовый запрос геонезависим:
Поистине, текущая логика работы языка запросов Яндекса непредсказуема. Сразу же возникает вопреки всякой элементарной логике шальная гипотеза изыскателя – а вдруг подобная рокировка поможет нам и без недокументированных «скобок»? Но не тут-то было, здесь Яндекс остается на удивление логичным:
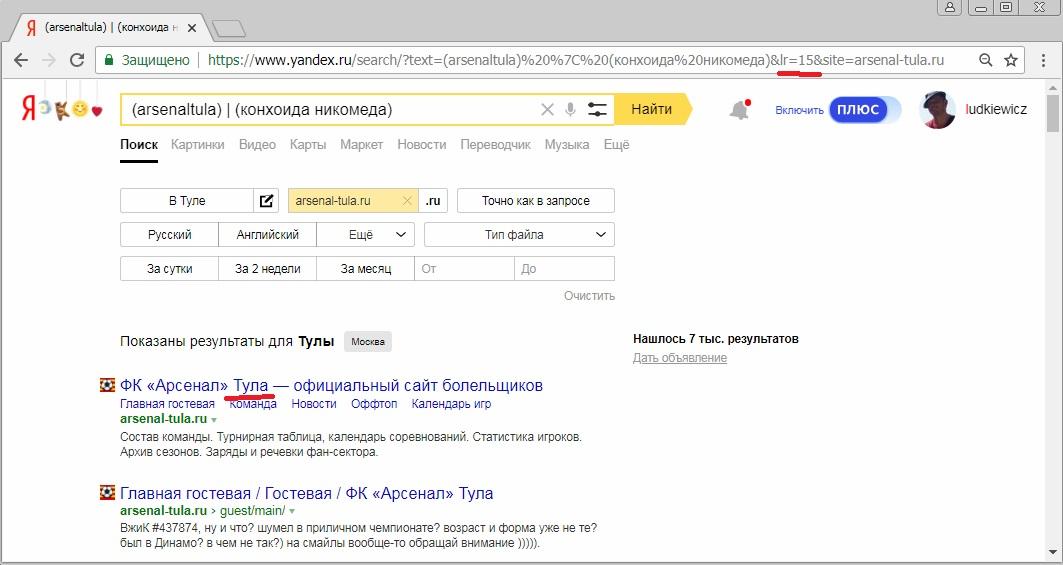
В общем, получаем понимание, что пока придется-таки использовать недокументированные «скобки». Напоследок убеждаемся, что для геозависимого исходного запроса, новый метод демонстрирует ожидаемую подсветку в сниппетах:
Что позволяет считать его вполне рабочим. В итоге берем новый метод на вооружение вместо прежнего, искренне надеясь, что коварная и непредсказуемая логика языка запросов Яндекса его в скором времени не испортит. Ну, а если и испортит, так все равно сможет найтись достойная альтернатива.
P.S. Замечено, что к сожалению, иногда в Яндексе глючит оператор | («логическое ИЛИ»), и метод выдает пустую выдачу. Но это не проблема метода, а проблема Яндекса. К счастью, пока довольно редко встречающаяся.