Новая логика работы операторов языка запросов Яндекса. Документные операторы
В своей предыдущей статье я проанализировал работоспособность операторов языка запросов Яндекса из группы «Морфология и поисковый контекст», о прекращении поддержки которых было официально объявлено Яндексом в январе 2017 года. Нововведения объяснялись «рядом важных изменений, направленных на увеличение производительности поиска, а именно изменением формата поискового индекса и связанным с ним изменением механизма разбора поисковых запросов». Вместе с тем изменения замечены и в работе другой группы операторов языка запросов Яндекса, а именно «Документные операторы».
Несмотря на то, что в документации языка запросов указано, что документные операторы используются для уточнения поискового запроса, ограничивая область его применения, раньше все операторы этой группы корректно работали и при их прямом применении (или, другими словами, в связке с пустым поисковым запросом). Теперь же эту способность сохранили только операторы url:, site:, host:, rhost:, domain: и date: (назовем их документными операторами 1-го типа). Операторы же mime:, lang: и cat: (назовем их документными операторами 2-го типа) при прямом применении работоспособность явно потеряли:

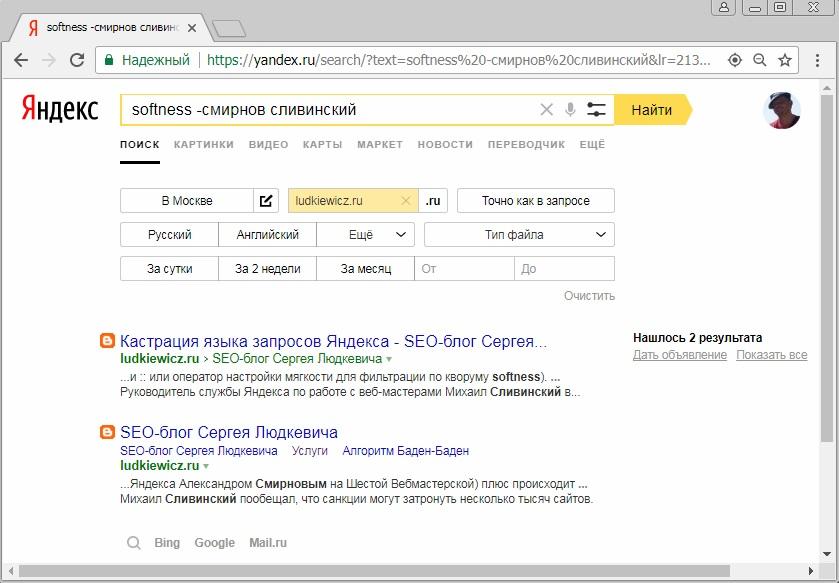
Документные операторы 2-го типа работают корректно только в связке с непустым запросом, причем, как справа, так и слева от него. Правда, при использовании этих операторов слева от непустого поискового запроса в выдаче могут возникать любопытные артефакты:

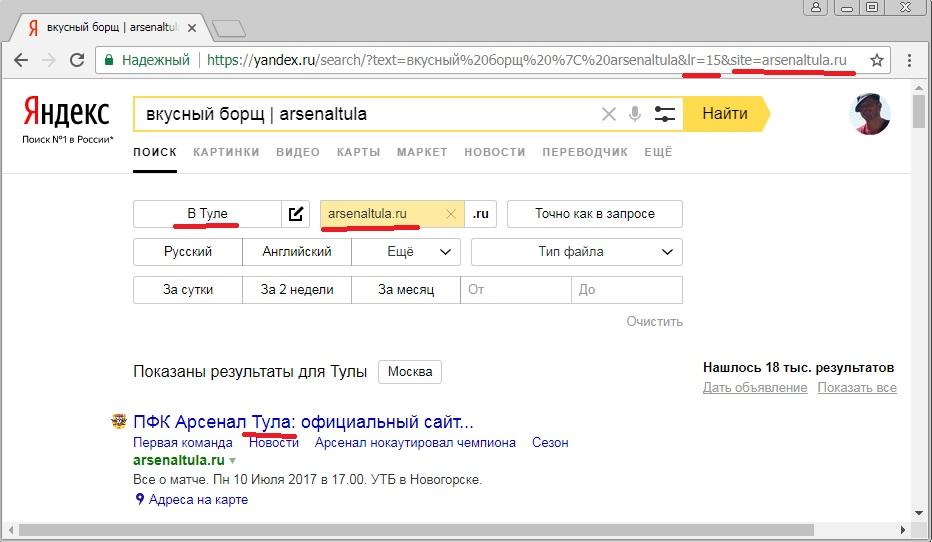
Есть также одно исключение, когда эти операторы корректно работают в случае пустого запроса – в связке с документным оператором site:, причем, только справа от него:

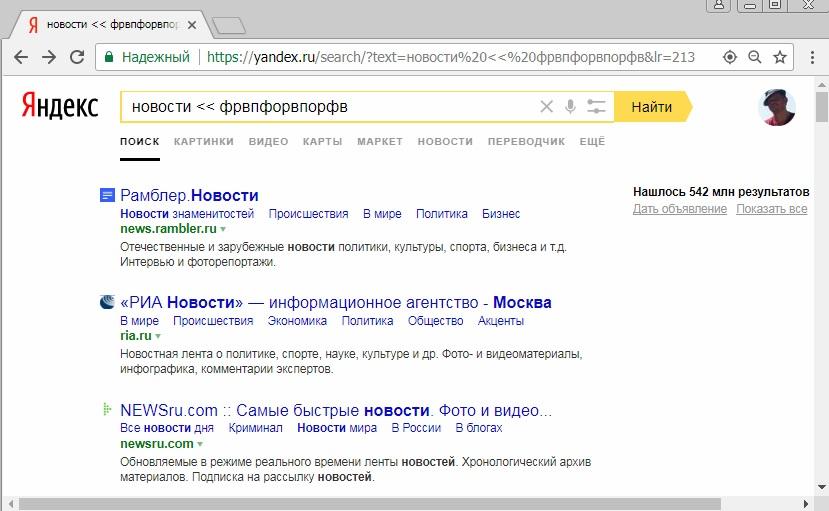
При использовании же слева от оператора site: документные операторы 2-го типа просто игнорируются:

Точно также документные операторы 2-го типа игнорируются и в случае пустого запроса в связке с операторами url:, host:, rhost:, domain: и date:, не зависимо от расположения справа или слева от них.
В случае же непустого запроса и нескольких документных операторов, порядок следования запроса и операторов роли не играет.
Представляется интересным также исследовать текущую работоспособность документных операторов, когда-либо упоминавшихся, но в разное время исчезнувших из официальной документации языка запросов.
Так, летом 2016-го года из раздела Яндекс.Помощи «Документные операторы» без каких-либо объявлений исчезли два оператора, сохранив, однако, на тот момент свою работоспособность:
- title: – оператор поиска по заголовкам документов (тег title);
- inurl: – оператор поиска по страницам, в адресе которых есть заданный фрагмент.
Сейчас оператор title: явно перестал выполнять заявленную функцию, такое впечатление, что он просто игнорируется, не зависимо от того, используется ли он с пустым или непустым поисковым запросом:



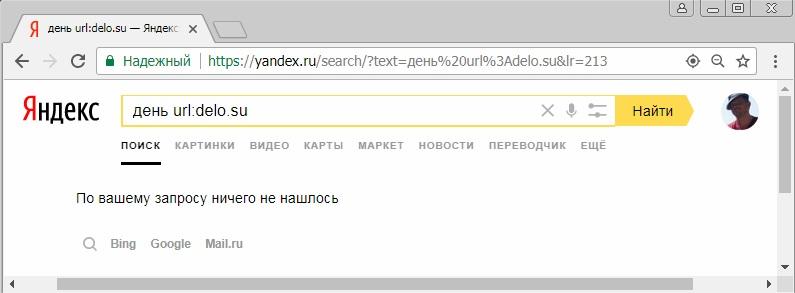
А вот оператор inurl:, в отличие от него, свою работоспособность сохранил. Так же, как и документированные документные операторы 2-го типа, он не работает при применении с пустым поисковым запросом

и работает в связке с непустым:

О других недокументированных операторах я в своё время писал в своих статьях «Сеанс поисковой магии. Недокументированные операторы языка запросов Яндекса» и «Недокументированные операторы языка запросов Яндекса. Продолжение сеанса поисковой магии». К сожалению, самые из них интересные операторы intext: и inlink: потеряли свою работоспособность в апреле 2017-го года, а операторы linkint: и anchorint: – еще раньше.
Из числа недокументированных работоспособными на текущий момент остаются только гораздо менее интересные для решения аналитических задач документные операторы:
- idate: – оператор поиска по дате последней индексации документа;
- style: – оператор поиска по адресам файлов таблиц стилей (значение атрибута href тега link c атрибутом stylesheet);
- profile: – оператор поиска по адресам профилей метаданных (значение атрибута profile тега head)
Все эти операторы имеют свойства документных операторов 2-го типа.